陆奇,奇绩创坛创始人兼CEO,曾任百度集团总裁兼首席运营官、微软全球执行副总裁、雅虎执行副总裁,卡内基梅隆大学计算机科学博士。作为人工智能全球顶级专家,陆奇自今年以来,以“大模型带来的变革和机会”为主题,先后在上海、深圳、北京等城市发表了多场演讲,进一步引发了业界对大模型的关注和思考。
大模型推动生产力从算力向机器智力跃升。生产力的变革是推动人类社会进步的根本动力,从原始社会、农业社会、工业社会到信息社会,背后是人力、畜力、电力到算力的跃升。随着大模型成为新的物种,机器智力将成为新的主流生产力。机器智力是智能算力与人类知识的扩展、集成和融合,大模型是机器智力的载体。随着大模型的不断进化和普及,其将成为经济社会的主流生产工具,重塑经济社会的生产方式,全面降低生产成本,提升经济效益。
大模型推动数字社会向智能社会跃升。首先是AI特别是AGI产业高度发展,带动智能算力相关基础设施投资,并基于大模型衍生出多种新业态和新市场,成为经济增长的核心引擎。以智算中心为例,一个单位的智算中心投资,可带动AI核心产业增长约2.9-3.4倍、带动相关产业增长约36-42倍。产业将加快智能化升级,张亚勤也认为GPT等各种大模型是人工智能时代的“操作系统”,将重构、重写数字化应用。其次是有了AGI的加持,人类的能力和活动范围都将得到大幅提升,进一步从重复性的脑力劳动中解放出来。但是,需要注意到,大模型的普及也会给现有的教育、就业、舆论甚至全球的政治格局带来冲击,是需要政府和产业界共同研究的问题。

 图1:AI大模型发展的三个阶段
图1:AI大模型发展的三个阶段1956年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI发展由最开始基于小规模专家知识逐步发展为基于机器学习。1980年,卷积神经网络的雏形CNN诞生。1998年,现代卷积神经网络的基本结构LeNet-5诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
探索沉淀期(2006-2019):以Transformer为代表的全新神经网络模型阶段
2013年,自然语言处理模型 Word2Vec诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。2014年,被誉为21世纪最强大算法模型之一的GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。2018年,OpenAI和Google分别发布了GPT-1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以Transformer为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
迅猛发展期(2020-至今):以GPT为代表的预训练大模型阶段
2020年,OpenAI公司推出了GPT-3,模型参数规模达到了1750亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。2022年11月,搭载了GPT3.5的ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。2023年3月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如ChatGPT的巨大成功,就是在微软Azure强大的算力以及wiki等海量数据支持下,在Transformer架构基础上,坚持GPT模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
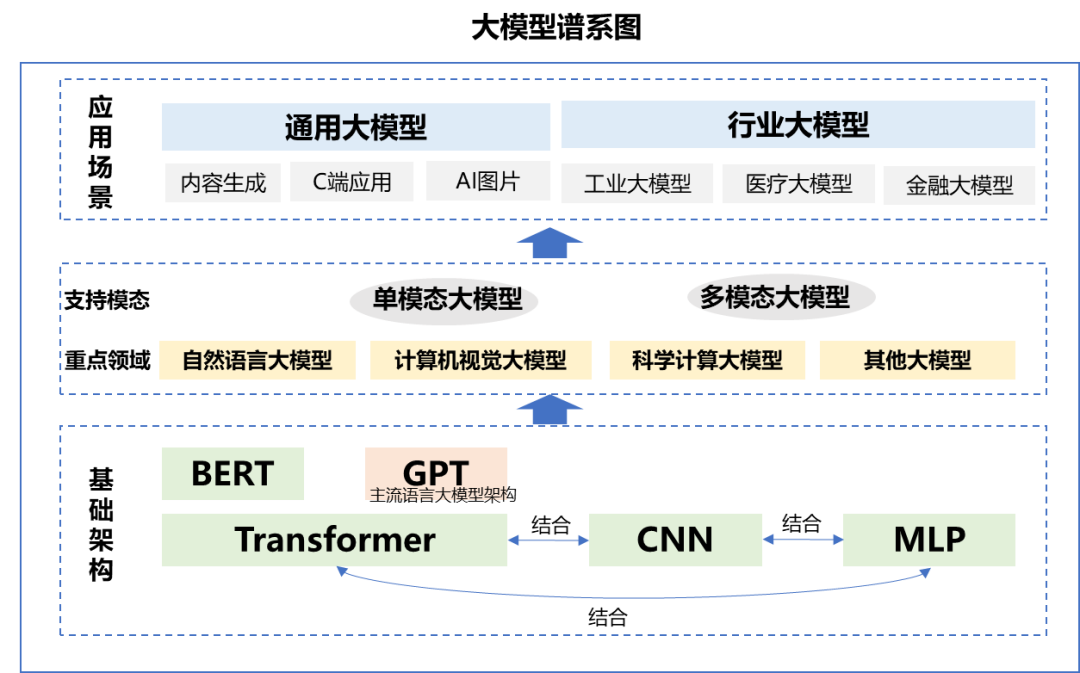
从技术架构上看, Transformer架构是当前大模型领域主流的算法架构基础,其上形成了GPT和BERT两条主要的技术路线,其中BERT最有名的落地项目是谷歌的AlphaGo。在GPT3.0发布后,GPT逐渐成为大模型的主流路线。综合来看,当前几乎所有参数规模超过千亿的大型语言模型都采取GPT模式,如百度文心一言,阿里发布的通义千问等。
从模态上来看,大模型可分为自然语言处理大模型,CV大模型、科学计算大模型等。大模型支持的模态数量更加多样,从支持文本、图片、图像、语音单一模态下的单一任务,逐渐发展为支持多种模态下的多种任务。
从应用领域来讲,大模型可分为通用大模型和行业大模型两种。通用大模型是具有强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于AI完成了“通识教育”,chatgpt、华为的盘古都是通用大模型。行业大模型则是利用行业知识对大模型进行微调,让AI完成“专业教育”,以满足在能源、金融、制造、传媒等不同领域的需求,如金融领域的BloombergGPT、法律领域的LawGPT_zh,以及百度基于文心大模型推出的航天-百度文心、辞海-百度文心等。

其次是策略精调。目的是让模型具备适用性,能与人类正常交流,即让基座模型理解用户想问什么,以及自己答的对不对。这个环节主要通过高质量的人工标注<指令,答案>(即prompt工程)优化模型。ChatGPT的标注数据集主要由一个 30-50 名 OpenAI 员工组成的团队和从第三方网站雇佣的50-100名标注员共同完成。 这个过程可以理解为老师给学生上课,讲解很多诗句的含义。引导他看到“孤独(prompt)”可以写“拣尽寒枝不肯栖,寂寞沙洲冷(答案)”,看到“豪情(prompt)”,可以写“愿将腰下剑,直为斩楼兰(答案)”
第三步是训练一个独立于基座模型的判别模型,用来判断模型生成结果的质量,为下一步的强化学习做准备。由专门的标注人员对模型生成的结果按照相关性、富含信息性、有害信息等诸多标准进行排序,然后通过判别模型学习标注好排名的数据,形成对生成结果质量判别能力。这一步是为小朋友培养一个伴读。通过给定一组题目(prompt),让小朋友为每一个题目写多篇古诗。由老师为每一首诗打分(结果标注),然后将结果告诉伴读。伴读需要学会判断哪首诗更符合题目,写的更有意境。
最后一步是利用奖励机制优化基座模型,完成模型的领域泛化能力。本阶段无需人工标注数据,而是利用强化学习技术,根据上一阶段判别模型的打分结果来更新内容生成模型参数,从而提升内容生成模型的回答质量。(第三和最后一步相当于大人去纠正小孩对话,告诉孩子哪句话是对的,哪句话不能这么回答,比如“爸爸好不好?”,回答“爸爸是坏蛋”就要进行“惩罚”,回答“爸爸很好,我很喜欢爸爸”就比较符合要求。类似的做法,实际的工作比这个要复杂的多,需要大量的专家投入)。这一步则是让伴读提升小朋友的水平,而老师则可以休息了。伴读告诉小朋友,如果用“未若柳絮因风起”描写雪则可以有糖葫芦吃,如果用“撒盐空中差可拟”描写则没有糖吃。通过反复练习,最后就可以培养出一位“能诗会赋”的高手(成品大模型)。
目前业界还没有形成统一的权威第三方评测方法,主要的评测手段有两类:
一类是深度学习常用的语言理解数据集与评测指标,即通过运行标准的数据集,来评测大模型的深度学习性能,常用的指标有准确率、召回率等。Meta、谷歌和华盛顿大学等合作推出的SuperGLUE(超级通用语言理解评估)包含7个任务的集合,能够测试大模型在回答问题和常识推理等多方面的能力。
另一类是面向大模型的文本生成、语言理解、知识问答等能力,设计专门评估指标体系,然后通过提问(prompt)的方式,根据生成的结果对模型进行评价。具体操作上又分为人工评测和裁判大模型评测两种方式,人工评测由语言学家和领域专家根据主观判断来评价模型各个指标的表现,如OpenAI等机构邀请研究人员评测GPT系列模型;科大讯飞牵头设计了通用认知大模型评测体系,从文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力和多模态能力这7个维度481个细分任务类型进行评估。裁判大模型评测是指用一个较强大的语言模型来评测其他语言模型。例如,用GPT-4模型作为“老师”,通过“老师”出题及评判其他模型的答案来实现机器评测。北大和西湖大学开源的裁判大模型pandaLM也实现了自动化、保护隐私和低成本的评估方式。
上述三种方式各有优缺点,语言理解数据集适用于初步评估大模型的基本性能,如翻译质量、语言表达能力等;人工评测适用于评估大模型的高层语言表达能力、情感理解力和交互性能等;机器裁判评测适用于对大规模数据和模型进行快速评测,评估大模型的稳定性和一致性。
1)互联网应用或SaaS应用: 直接向终端用户提供大模型SaaS应用产品,通过订阅模式、按生成内容的数量或质量收费、按比例分成等模式实现盈利,例如Midjourney提供每月10美元和30美元两种会员收费标准;ChatGPT对用户免费,但ChatGPT plus收费20美元/月。
2)“插件”(Plug in): 大模型可集成加载第三方应用产品插件,大大拓展了大模型的应用场景,吸引更多用户,例如ChatGPT Plugins,大量餐饮、商旅网站和APP通过插件加载集成到ChatGPT,增强了ChatGPT的功能和体验,用户不是简单的聊天,而是可以一站式实现综合任务,例如出差或旅游,大模型可以帮忙订机票,订酒店,订饭店和租车等等。
3)自有应用重构: 将自研的大模型能力直接内置嵌入自有应用,增强智能辅助和高效交互,为自有应用引流增加收益,例如微软将GPT-4深度集成到Office、Bing等系列产品,功能要强大的多,例如搜索可以对话式获取更聪明精确和综合的答案,office可以为辅助客户撰写PPT和文档,只需说出需求,ChatGPT即可快速生成一份模板化文档,大差不差,稍作修改即可使用,大大提升了工作效率。
4)开放API: 大模型平台开放API,为开发者提供可访问和调用的大模型能力,按照数据请求量和实际计算量计费,开发者可以根据需要开发定制功能和应用,国内一些ChatGPT小程序和web应用就是基于ChatGPT的API外包一层UI提供的,国内商汤“日日新”大模型也为用户开放API接口;
5)大模型云服务: 基于大模型和配套算力基础设施提供全套模型服务,如为客户提供自动化数据标注、模型训练、提供微调工具等以及增量支撑服务,按照数据请求量和实际计算量计费,例如Azure OpenAI服务,客户可开发训练自己的大模型,未来不提供大模型框架、工具和数据集处理能力的云将很难吸引客户“上云”;
6)解决方案: 提供定制化或场景化的行业应用解决方案,按具体项目实施情况收费,例如科大讯飞智能客服解决方案,这种按项目和解决方案部署AI和大模型应用适用于行业大客户,投入成本较高。
1)、2)、4)可依托第三方大模型能力快速开展业务,但同时失去对数据的掌控,2)和4)通过开放促进大模型应用生态发展,ChatGPT实现从聊天工具到类OS的跃升;3)门槛较高,需要自主研发或部署大模型,掌控大模型能力,但可以深度提升应用能力;5)主要面向有模型自主开发需求的客户;6)主要面向2B客户,可通过私有化部署保障数据安全。
未来,大模型与机器人、智能设备等硬件结合(大模型拥有“手脚”),将为商业模式创新带来更广阔的空间。
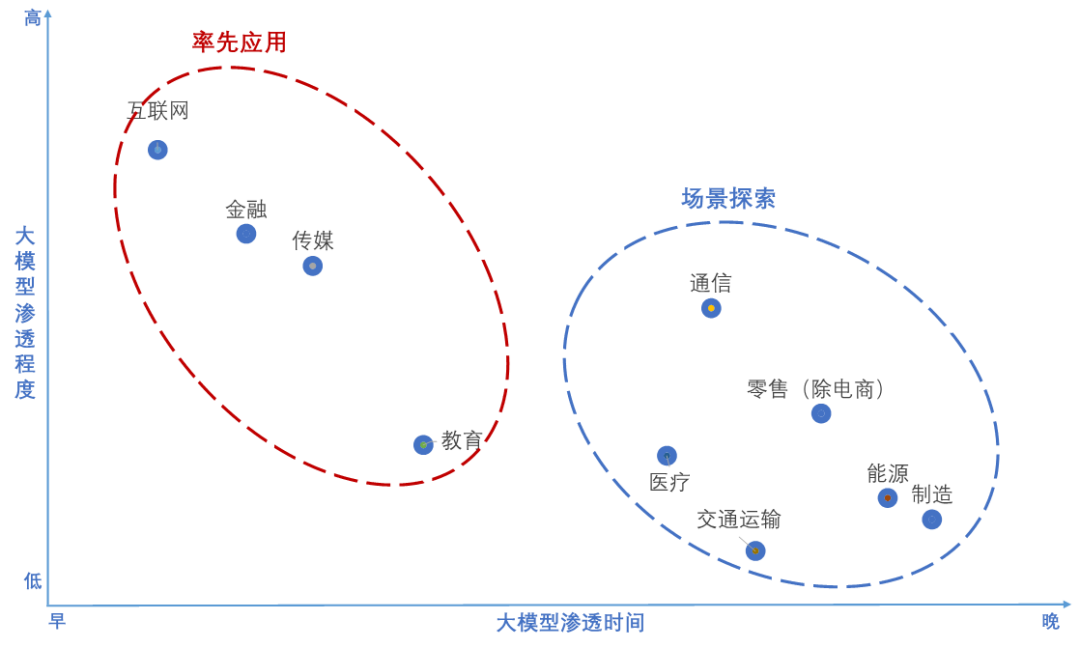
未来,大模型在医疗、交通、制造等行业的长期渗透潜力大。当前医疗、交通、制造等专业领域正积极探索大模型应用场景,如中文医疗语言大模型“商量·大医”通过多轮对话辅助支持导诊、问诊、健康咨询等场景;百度基于交通大模型的全域信控缓堵方案可实现15-30%的效率提升;华为盘古大模型在矿山、电力等领域通过“预训练+微调”方式打造细分场景模型方案,如煤矿场景下可降低井下安全事故90%以上。未来随着行业数字化程度进一步提升、人工智能治理法律法规进一步完善,大模型在上述领域的应用将迎来爆发。
随后,大模型开源将促进新开发生态的形成,实现“智能原生”。开发者可以基于开源模型利用专有数据资料在本地进行开发训练,如加州大学伯克利分校、CMU、斯坦福大学、加州大学圣地亚哥分校的研究人员联合推出Vicuna,达到OpenAI ChatGPT 90%以上水平,训练成本仅需300美元。开源模型解决了大模型可扩展的问题,同时将大模型的训练门槛从企业级降低到消费级,个人开发者利用电脑设备均能基于开源大模型进行定制化、本地化训练。未来基于开源大模型的定制版或将部署在云、边、端各个环节,带来云端和多云应用的重构和联结。
版权归原作者所有,如若转载,请注明出处:https://www.ciocso.com/article/466981.html

